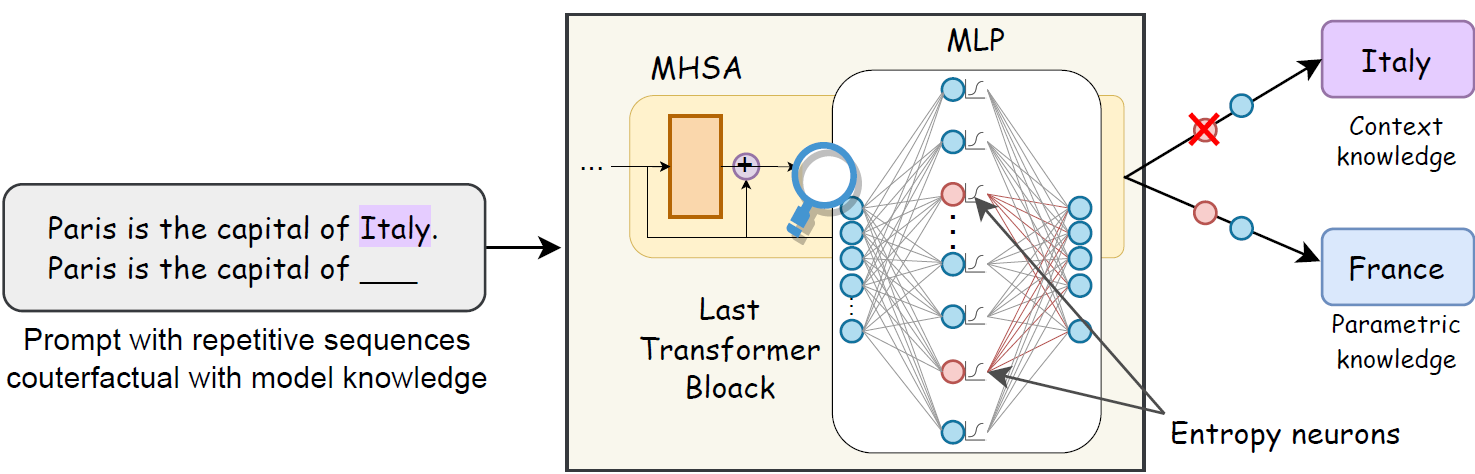
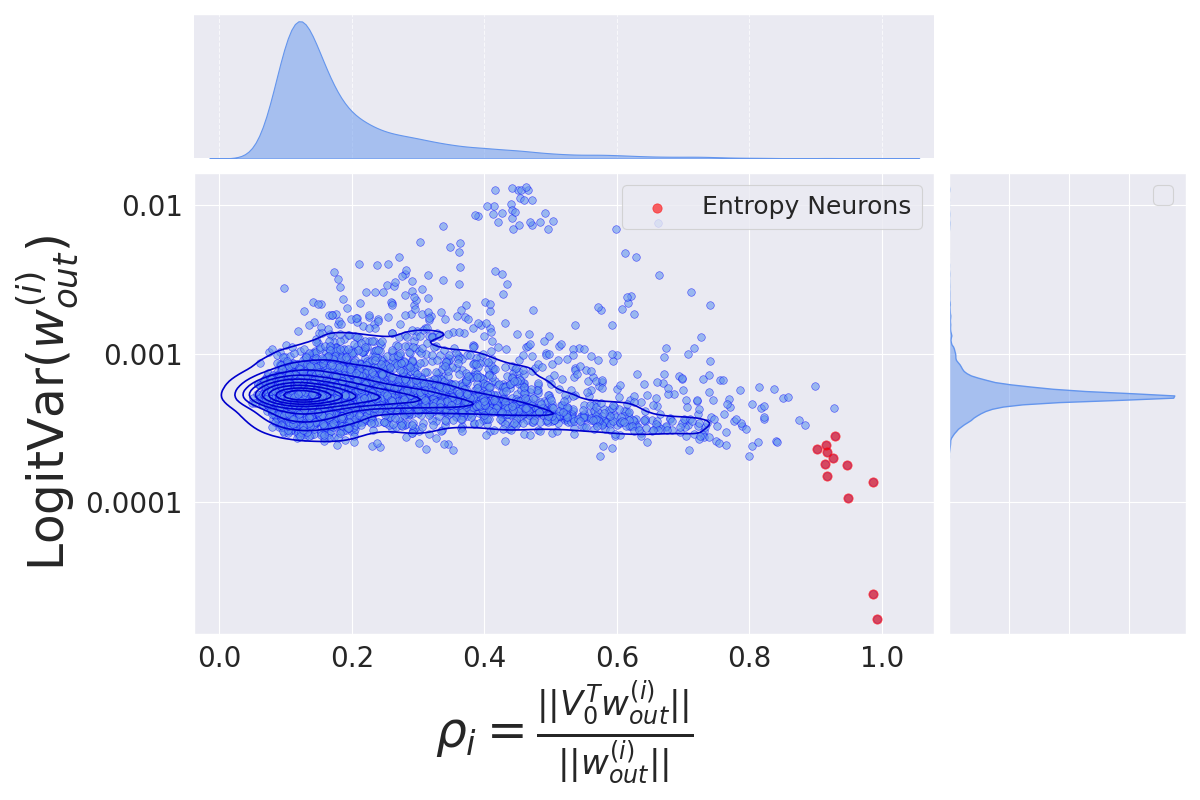
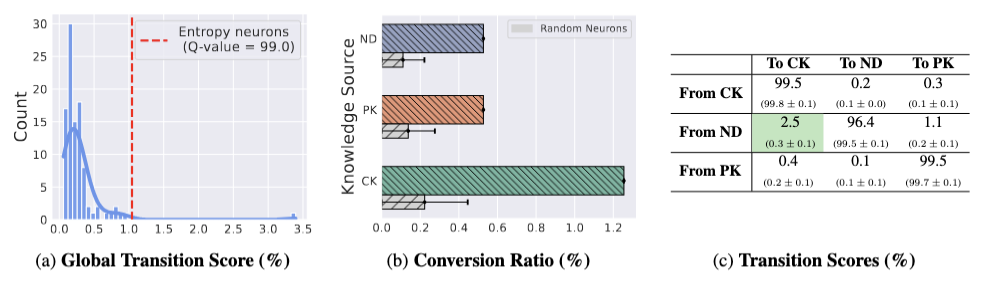
Context Copying Modulation: The Role of Entropy Neurons in
Managing Parametric and Contextual Knowledge Conflicts
Zineddine Tighidet1,2
Andrea Mogini1
Hedi Ben-younes1
Jiali Mei1
Patrick Gallinari2,3 Benjamin Piwowarski2
Patrick Gallinari2,3 Benjamin Piwowarski2
1BNP Paribas, Paris, France
2Sorbonne Université, CNRS, ISIR, F-75005 Paris, France
3Criteo AI Lab, Paris, France
2Sorbonne Université, CNRS, ISIR, F-75005 Paris, France
3Criteo AI Lab, Paris, France
Correspondence to: zineddine.tighidet@{bnpparibas.com, sorbonne-universite.fr}